

Có lẽ các bạn đã nghe nói đến kỹ thuật crawl dữ liệu website đâu đó rồi đúng không? Đây là kỹ thuật để thu thập dữ liệu khá phổ biến, ví dụ như Google bot cũng là một hình thức của crawler.
Kỹ thuật crawler có rất nhiều ứng dụng thực tế, có thể kể đến một số ý tưởng như: Xây dựng ứng dụng đọc báo bằng cách crawl dữ liệu website từ các báo lớn, crawl các thông tin tuyển dụng từ Facebook.v.v…
Để tạo một web crawler có rất nhiều cách, và cũng có vô số framework hỗ trợ. Ví dụ như Python thì có Scrapy rất nổi tiếng. Tuy nhiên, do mình chỉ biết có Nodejs thôi, nên bài viết này chúng ta sẽ cùng nhau tìm hiểu kỹ thuật crawler dữ liệu website sử dụng kỹ thuật phân tích cú pháp DOM bằng Nodejs.
Trước hết, để các bạn khỏi lăn tăn, Vntalking sẽ cùng các bạn đang muốn tự học lập trình xem crawler website là gì nhé.
Nội dung chính của bài viết
#Crawl dữ liệu website là gì?
Nói một cách dễ hiểu, thì web crawler là kỹ thuật thu thập dữ liệu từ các website trên mạng theo đường links cho trước. Các web crawler sẽ truy cập vào đường link và download toàn bộ dữ liệu cũng như tìm kiếm thêm các đường link bên trong để download nốt.
Nếu trong quá trình thu thập dữ liệu, bạn chỉ chắt lọc những thông tin cần thiết cho nhu câu cầu bạn thì người ta gọi là web Scaping.
Hai khái niệm web crawler và web scaping về cơ bản giống nhau, có khác nhau thì cũng thì tí xíu thôi à.
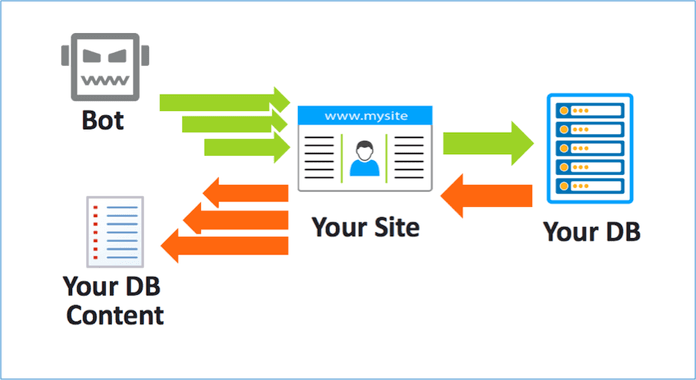
Ví dụ với trang shopee.com, kỹ thuật web crawling sẽ thu thập toàn bộ nội dung của trang web này (tên sản phẩm, mô tả sản phẩm, giá sản phẩm, hướng dẫn sử dụng, các đánh giá và bình luận về sản phẩm,…). Tuy nhiên, web scaping thì có thể chỉ thu thập một số thông tin cần thiết với bạn như: chỉ thu thập giá sản phẩm để làm ứng dụng so sánh giá.
Những dữ liệu khi crawl có thể được lưu trữ trong cơ sở dữ liệu của bạn để phục vụ việc phân tích hoặc sử dụng với mục đích khác nhau.
#Demo kỹ thuật crawler website
Để minh họa cho kỹ thuật crawl này, mình sẽ hướng dẫn các bạn xây dựng một con bot crawl dữ liệu từ website Scotch.io (một website nổi tiếng về dạy học lập trình).
Chúng ta sẽ crawl những dữ liệu về profile của một tác giả, cũng như những bài viết của anh ấy. Sau đó, xây dựng RESTful API để trả về những dữ liệu đó, mục đích để sử dụng cho app của chúng ta sau này.
Dưới đây là ảnh chụp màn hình ứng dụng demo được tạo dựa trên API mà chúng ta đã xây dựng trong bài viết này.

Một số yêu cầu trước khi thực hiện
Như mình đã nói, kỹ thuật crawl có thể thực hiện bởi hầu hết các ngôn ngữ lập trình hiện đại hỗ trợ HTTP, XML và DOM như: PHP , Python, Java, Javascript…
Trong bài viết này, mình sẽ sử dụng Javascript trên môi trường Nodejs để thực hiện crawling. Do vậy bạn cần có kiến thức cơ bản về Javascript để có thể đọc bài viết dễ dàng hơn và thực hành crawl website nodejs.
Nếu bạn chưa biết gì về Nodejs hay Javascript thì có thể tham khảo những bài viết này trước:
Trước khi bắt đầu code theo bài viết này, bạn cũng cần phải cài đặt sẵn sàng Nodejs và Npm trong máy của mình.
Ngoài ra, mình cũng có sử dụng một số thư viện 3rd party (Dependencies) hỗ trợ cho việc crawl như:
- Cheerio – hỗ trợ parsing DOM cực đơn giản. Thư viện này được cái nhẹ, dễ sử dụng và tốc độ nhanh.
- Axios – Hỗ trợ lấy content của webpage thông qua https request.
- Express – đây là web application framework quá nổi tiếng rồi. Có lẽ không cần phải nói gì thêm về nó nữa.
- Lodash – Là một thư viện dạng utility của Javascript. Nó viết sẵn rất nhiều hàm hay dùng về arrays, numbers, objects, strings…
Ok, nếu tất cả đã sẵn sàng, chúng ta bắt tay vào thực hiện viết crawling dữ liệu thôi.
#Xây dựng crawler website
Vẫn như mọi khi, để các bạn có thể dễ dàng đọc và làm theo, mình sẽ cố gắng viết chi tiết nhất có thể. Có chỗ nào không hiểu thì phải hỏi ngay nhé!
1. Cài đặt Dependencies
Đầu tiên, các bạn tạo một dự án Nodejs mới, sau đó cài đặt những thư viện cần thiết cho dự án.
# Create a new directory mkdir scotch-scraping # cd into the new directory cd scotch-scraping # Initiate a new package and install app dependencies npm init -y npm install express morgan axios cheerio lodash
2. Cài đặt webserver với Express
Chúng ta sẽ tạo một http server đơn giản bằng ExpressJS. Đơn giản là tạo mới tệp server.js trong thư mục gốc của dự án, sau đó thêm đoạn code sau:
/_ server.js _/
// Require dependencies
const logger = require('morgan');
const express = require('express');
// Create an Express application
const app = express();
// Configure the app port
const port = process.env.PORT || 3000;
app.set('port', port);
// Load middlewares
app.use(logger('dev'));
// Start the server and listen on the preconfigured port
app.listen(port, () => console.log(App started on port ${port}.))
Sau đó, bạn chỉnh sửa file package.json để chạy server đơn giản hơn. Thêm đoạn code sau:
"scripts": {
"start": "node server.js"
}
Với đoạn code trên thì từ nay, thay vì phải gõ: node server.js để khởi chạy code, bạn chỉ cần gõ: npm start.
Thực ra, nếu chỉ có vậy thì việc phải thêm script vào package.json cũng không có nhiều lợi ích lắm phải không? Tuy nhiên, sau này khi bạn cần phải làm nhiều tác vụ hơn mỗi khi chạy server như: copy file cấu hình, generate một đoạn mã nào đó trước khi start server thì bạn cũng chỉ phải cấu hình trong đoạn script start này thôi.
>>> Nên đọc: Cách parse Json Javascript chuẩn nhất
3. Tạo Request và Response Helper
Ở phần này, chúng ta sẽ tạo một số hàm để tái sử dụng trong toàn bộ ứng dụng.
Tạo mới một file helpers.js trong thư mục gốc của dự án.
/_ app/helpers.js _/
const _ = require('lodash');
const axios = require("axios");
const cheerio = require("cheerio");
Đoạn code trên, chúng ta mới chỉ import những thư viện cần thiết cho helper mà thôi. Giờ là lúc viết nội dung cho helper.
Đầu tiên, chúng ta sẽ tạo một để việc trả về dữ liệu JSON về cho requester đơn giản hơn.
/_ app/helpers.js _/
/**
**_ Handles the request(Promise) when it is fulfilled
_** and sends a JSON response to the HTTP response stream(res).
*/
const sendResponse = res => async request => {
return await request
.then(data => res.json({ status: "success", data }))
.catch(({ status: code = 500 }) =>
res.status(code).json({ status: "failure", code, message: code == 404 ? 'Not found.' : 'Request failed.' })
);
};
Ví dụ các sử dụng hàm này như sau:
app.get('/path', (req, res, next) => {
const request = Promise.resolve([1, 2, 3, 4, 5]);
sendResponse(res)(request);
});
Mình sẽ giải thích cụ thể hơn nhé. Khi server nhận một request: GET /path. Chúng ta giả định làm abcxyz gì đó và có kết quả là [1, 2, 3, 4, 5]. Lúc này hàm sendResponse() sẽ hỗ trợ trả JSON lại cho requester.
{
"status": "success",
"data": [1, 2, 3, 4, 5]
}
Tiếp theo là hàm get html từ một url bất kỳ.
/**
_ Loads the html string returned for the given URL
_ and sends a Cheerio parser instance of the loaded HTML
*/
const fetchHtmlFromUrl = async url => {
return await axios
.get(enforceHttpsUrl(url))
.then(response => cheerio.load(response.data))
.catch(error => {
error.status = (error.response && error.response.status) || 500;
throw error;
});
};
Đúng như trên gọi của nó, khi bạn gọi hàm này thì kết quả sẽ là toàn bộ html của URL. Từ “đống” HTML này, chúng ta sẽ bóc tách để lấy những dữ liệu cần thiết.
Trong file helper.js này còn có nhiều hàm khác nữa, nhưng do dài quá mình không tiện liệt kết ra đây. Bạn cứ lấy source về dùng, nếu có chỗ nào không hiểu thì để lại comment bên dưới nhé.
4. Tiến hành tạo file crawler website dữ liệu từ scotch
Tất cả những thủ tục cần thiết cho việc crawling dữ liệu đã chuẩn bị xong. Giờ là lúc chúng ta viết những hàm crawl, phân tích dữ liệu từ website.
Tạo file scotch.js trong thư mục app và thêm đoạn code sau:
/_ app/scotch.js _/
const _ = require('lodash');
// Import helper functions
const {
compose,
composeAsync,
extractNumber,
enforceHttpsUrl,
fetchHtmlFromUrl,
extractFromElems,
fromPairsToObject,
fetchElemInnerText,
fetchElemAttribute,
extractUrlAttribute
} = require("./helpers");
// scotch.io (Base URL)
const SCOTCH_BASE = "https://scotch.io";
///////////////////////////////////////////////////////////////////////////////
// HELPER FUNCTIONS
///////////////////////////////////////////////////////////////////////////////
/*
Resolves the url as relative to the base scotch url
and returns the full URL
/
const scotchRelativeUrl = url =>
_.isString(url) ? ${SCOTCH_BASE}${url.replace(/^\/*?/, "/")} : null;
/_*
_ A composed function that extracts a url from element attribute,
_ resolves it to the Scotch base url and returns the url with https
*/
const extractScotchUrlAttribute = attr =>
compose(enforceHttpsUrl, scotchRelativeUrl, fetchElemAttribute(attr));
Trong đó, cần lưu ý đến hàm scotchRelativeUrl(): Hàm này có mục đích là tự động trả về full URL khi chúng ta chỉ cần truyền vào param URL.
Ví dụ:
scotchRelativeUrl('tutorials');
// returns => 'https://scotch.io/tutorials'
scotchRelativeUrl('//tutorials');
// returns => 'https://scotch.io///tutorials'
scotchRelativeUrl('http://domain.com');
// returns => 'https://scotch.io/http://domain.com'
3. Trích xuất dữ liệu từ website
Trong phần này, chúng ta sẽ tiến hành trích xuất những thông tin cần thiết như:
- social links (facebook, twitter, github, …)
- profile (name, role, avatar,…)
- stats (total views, total posts, …)
- posts
Tuy nhiên, do bài viết quá dài nên mình sẽ chỉ giải thích cho phần đầu tiền ( lấy social link của một tác giả). Các phần còn lại, các bạn tham khảo trong source code nhé.
Để có thể trích xuất dữ liệu social link của một ai đó trên scotch.io, mình sẽ định nghĩa một hàm extractSocialUrl() trong file scotch.js. Mục đích của hàm này là trích xuất tên mạng social, URL trong thẻ <a>.
Mình ví dụ một DOM về thể <a> trong profile của một tác giả trên scotch.
<a href="https://github.com/gladchinda" target="_blank" title="GitHub">
<span class="icon icon-github">
<svg xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" version="1.1" id="Capa_1" x="0px" y="0px" width="50" height="50" viewBox="0 0 512 512" style="enable-background:new 0 0 512 512;" xml:space="preserve">
...
</svg>
</span>
</a>
Khi gọi hàm extractSocialUrl() thì kết quả trả về là một object kiểu như sau:
{ github: 'https://github.com/gladchinda' }
Đoạn code hoàn chỉnh của hàm t rích xuất social link như sau:
/_ app/scotch.js _/
///////////////////////////////////////////////////////////////////////////////
// EXTRACTION FUNCTIONS
///////////////////////////////////////////////////////////////////////////////
/_*
_ Extract a single social URL pair from container element
*/
const extractSocialUrl = elem => {
// Find all social-icon <span> elements
const icon = elem.find('span.icon');
// Regex for social classes
const regex = /^(?:icon|color)-(.+)$/;
// Extracts only social classes from the class attribute
const onlySocialClasses = regex => (classes = '') => classes
.replace(/\s+/g, ' ')
.split(' ')
.filter(classname => regex.test(classname));
// Gets the social network name from a class name
const getSocialFromClasses = regex => classes => {
let social = null;
const [classname = null] = classes;
if (_.isString(classname)) {
const _[_, name = null] = classname.match(regex);
social = name ? _.snakeCase(name) : null;
}
return social;
};
// Extract the href URL from the element
const href = extractUrlAttribute('href')(elem);
// Get the social-network name using a composed function
const social = compose(
getSocialFromClasses(regex),
onlySocialClasses(regex),
fetchElemAttribute('class')
)(icon);
// Return an object of social-network-name(key) and social-link(value)
// Else return null if no social-network-name was found
return social && { [social]: href };
};
Mình sẽ giải thích một chút:
- Đầu tiên, mình sẽ tìm nạp (fetch) những thẻ <span> với icon class. Mình cũng định nghĩa một regular expression để matching với icon class
- Chúng ta có định nghĩa một hàm
onlySocialClasses()có nhiệm vụ trích xuất tất cả class liên quan đến social.
Ví dụ cụ thể cho dễ hiểu nhé: hàm này sẽ trả về các class liên quan đến social.
const regex = /^(?:icon|color)-(.+)$/; const extractSocial = onlySocialClasses(regex); const classNames = 'first-class another-class color-twitter icon-github'; extractSocial(classNames); //returns [ 'color-twitter', 'icon-github'
Tiếp theo, để trích xuất được tên mạng social thì sử dụng hàm extracSocialName()
const regex = /^(?:icon|color)-(.+)$/; const extractSocialName = getSocialFromClasses(regex); const classNames = [ 'color-twitter', 'icon-github' ]; extractSocialName(classNames); // returns 'twitter'
Cuối cùng là trích xuất URL từ href attribute. Kết quả thu được như sau:
{ twitter: 'https://twitter.com/gladchinda' }
#Tổng kết
Như vậy, mình đã hướng dẫn các bạn từng bước để có thể crawler website online. Có thể mỗi website khác nhau sẽ có cấu trúc HTML khác nhau nên có thể bạn sẽ cần update lại các extractor cho phù hợp. Nhưng về tổng thể thì cũng giống như thế này thôi.
Các bạn có thể download toàn bộ source code của bài hướng dẫn tại đây:
Hi vọng qua bài viết này, các bạn sẽ hiểu rõ về kỹ thuật crawl dữ liệu từ các website, cũng không kinh khủng lắm phải không!

Nhận sách Java Advanced Features
Java là ngôn ngữ lập trình phổ biến nhất thế giới, là hình mẫu của tư tưởng OOP. Nếu bạn muốn bắt đầu với Java thì đây là cuốn sách không thể bỏ qua. Với 63 ví dụ thực hành, cùng với cách viết ngắn gọn dễ hiểu sẽ giúp bạn hiểu rõ bản chất của Java.
Hiện Amazon đang bán với giá 16$, nhưng với VNTALKING thì miễn phí cho bạn. Còn chờ gì nữa?










")



![[Tự học Javascript] Giải thích chi tiết về Event Loop](https://vntalking.com/wp-content/uploads/2021/11/event-loop-in-javascript-100x70.png "[Tự học Javascript] Giải thích chi tiết về Event Loop")





thế với những web CSR , data được gọi từ phía client thì có cách nào crawl data không ạ?
Mình nghĩ là không bạn à.
Mình đang crawl thẻ với cheerio, axios Ko hiểu sao mình ko thể tìm được thẻ pre? My code: const axios = require(‘axios’); const http = require(‘http’); const fs = require(‘fs’); const cheerio = require(“cheerio”); const request = require(“request”); const url = “http://gamesradar.com”; const jsdom = require(“jsdom”); const {JSDOM} = jsdom; const urlAds = “http://gamesradar.com/ads.txt”; //const urlAds = “http://haianfishmeal.com/ads.txt”; const options = { url: urlAds, method: ‘GET’, headers: { ‘Accept’: ‘application/json’, ‘Accept-Charset’: ‘utf-8’, ‘User-Agent’: ‘my-reddit-client’ } }; request(options, function (err, res, body) { if (err) { console.log(err); } else { const dom = new JSDOM(body); console.log(dom.window.document.querySelectorAll(“body pre”)); } }); Cám… Đọc thêm »
sendResponse = res => async request / sendResponse(res)(request) : đoạn này mình không hiểu , bạn có thể cho key word mình tìm hiểu được không b. mình không biết tại sao lại viết được như vậy
Chào bạn Quyết,
Keyword tìm hiểu chỗ đó gồm 2 kiến thức: async wait và arrow function.
https://vntalking.com/toan-tap-ve-javascript-async-await-tai-sao-lai-nen-dung.html
ý mình hỏi cách viết kiểu viết : (res)(request) , nó có giông với (res, request) không. mình không biết sao lại viết được như vậy
Bạn để ý phần định nghĩa hàm sendResponse nhé. Đó là cách viết tắt theo kiểu arrow function thôi. Nếu viết đầy đủ thì sẽ thế này: function sendResponse (res, function (request){…}}. Do vậy, khi sử dụng hàm này thì cách viết sendResponse(res)(request) sẽ tương đương sendResponse(res, function (request){{…}}. Tóm lại keyword vẫn là liên quan tới arrow function thôi bạn à
thanks ban nha, tai minh chua thay kieu viet nhu vay bao gio, bay gio minh hieu roi
Hi bạn,
Khi crawler Code này có vượt qua được bot, Captcha không ?
Cái này thì tùy vào ông admin của website mà bạn định crawler nhé. Nếu họ config cẩn thận, chặn bot crawler thì có thể sẽ gặp captcha
Chào Sơn Dương, mình đang cần 1 solution cho crawler webpage, cần tư vấn của bạn. Thanks
Chào bạn,
Bạn cần mình support gì vậy?
Mình đang muốn build web để crawler dữ liệu từ một sống trang bất động sản, bạn có triển khai được không? Nếu được trao đổi cụ thể với mình nhé: 0971976697 (zalo)
Bạn có nhận crawl dữ liệu k, nếu có vui lòng gửi mail cho mình nhé, giá cả mình trao đổi rõ hơn, mail mình [email protected]
Chào bạn Duy,
Hiện tại thì bên mình chưa có dịch vụ crawl dữ liệu bạn à. mong bạn thông cảm
.
e chua thay code a gửi qua mail cho em vói.
e cảm ơn
Hi,
Mình gửi source code cho bạn rồi nhé
MÌnh ấn like rồi mà không hiển thị phần tải code về nhỉ ?? . Bạn có thể gửi mail cho mình dk không . Mình cảm ơn
Hi, bạn kiểm tra email nhé.
Mình đã nhận được mail nhưng ko thấy phần tải code đâu ?? . Bạn check lại giúp mình vs
Hi
Mã nguồn được mình upload lên Github nên bạn dùng lệnh git để download về nhé: git clone [email protected]:vntalking/demo-crawler-website.git. Lưu ý là cần phải cài đặt git trong PC trc đó rồi. Hoặc không, bạn nhìn thấy button: clone or download sau đó chọn download zip về là được. Thanks
Hi. Bạn cho link ý phải có key mới clone dk . Permission denied (publickey ). \
bạn tham khảo hình bên dưới để biết cách download nhé

mình đã like nhưng không thấy được source code, bạn có thể gửi qua email cho mình được k? Cảm ơn bạn
Hi
Mình gửi source code qua email cho bạn rồi nhé. Bạn kiểm tra inbox nhé
Cần đặt hàng Lấy tin bds về wweb minhv
Hi bạn, mình like rồi nhưng vẫn không hiện chỗ download sourcecode ạ
Hi
Chắc do cái social lock đôi lúc bị lỗi. Bạn có thể unlike, sau đó reload trình duyệt rồi thử like lại giúp mình nhé.
Nếu vẫn không được thì bảo mình để mình gửi bạn mail nhé!
Hi bạn nó vẫn lỗi 🙁 bạn gửi giúp mình source qua email nha: [email protected]. Cám ơn bạn nhiều nha
Mình gửi mã nguồn qua email cho bạn rồi nhé